Serverless GenAI PDF Chat
RAG Chatbot with AWS Bedrock and LangChain
AWS LambdaAmazon BedrockLangChain.jsPineconeNode.jsReactServerless FrameworkRAG
interview-challenge
Serverless GenAI PDF Chat (AWS Bedrock + LangChain)
A serverless, production-style GenAI chatbot designed to allow users (e.g., maintenance technicians) to ask natural-language questions about large PDF documents (like operational manuals) and receive accurate, contextual answers.
Built as part of a Founding Product Engineer interview challenge to demonstrate real-world problem-solving, cloud architecture, and GenAI integration.
Problem Statement: Bridging the Manual Gap
Organizations maintain extensive collections of technical manuals, operational guides, and safety documents that span hundreds or thousands of pages. Extracting precise answers from these documents is time-consuming, as relevant information is often buried across multiple files and sections.There is a need for a system that allows users to ask natural-language questions directly to a large set of documents and receive concise, accurate answers without manually searching through each document.
Example Queries:
- “What are the steps I need to follow for the inspection?”
- “What safety steps are required before starting the machine?”
This project implements Retrieval-Augmented Generation (RAG) to replace manual document search with an intelligent, GenAI-powered chat interface.
Architecture Overview: Fully Serverless RAG Pipeline
The solution is Fully Serverless, Scalable, and AWS-Native.

Technology Flow
Layer | Technologies | Description |
|---|---|---|
Frontend | React, S3, CloudFront | User interface for document upload and chat; hosted statically. |
Edge/API | API Gateway | Exposes a secure REST API endpoint. |
Backend / Compute | AWS Lambda (Node.js) | Handles all core logic including ingestion, RAG, and communication. |
GenAI | Amazon Bedrock (LLAMA2, Claude) | Large Language Models used for generating contextual answers. |
Vector DB | Pinecone | Stores embedded document chunks for efficient retrieval. |
Storage | Amazon S3 | Stores raw PDF documents. |
IaC | Serverless Framework | Infrastructure as Code for deploying the entire stack. |
Key Design Principles
- No servers to manage
- Data stays within AWS
- Stateless backend
- Scalable and cost-efficient
- Built with real-world GenAI constraints in mind
Core Features
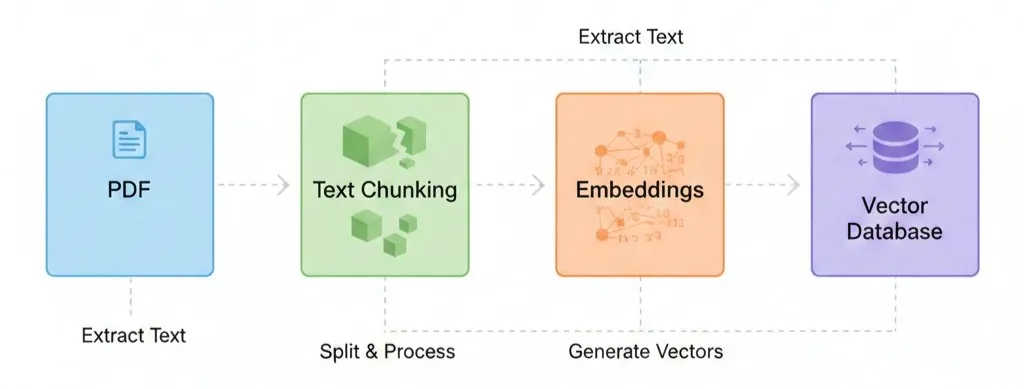
PDF Ingestion Pipeline
The system transforms raw PDFs into a searchable vector index:
- User uploads PDF document.
- Lambda extracts text and splits it into semantic chunks.
- Embeddings are generated using Bedrock.
- Vectors are stored in Pinecone with isolated namespaces.
Intelligent Document Chat
- Performs Retrieval-Augmented Generation (RAG) over the ingested PDFs.
- Provides accurate, context-aware responses to natural-language queries.
- Uses Per-chat namespace isolation in Pinecone to prevent cross-document leakage and ensure context integrity.
Multi-Model Support (Bonus)
The architecture supports switching the underlying LLM:
- LLAMA2
- Claude
This allows for easy comparison of outputs from the same prompt across different models.
Prompt Engineering Highlights
Optimized the LLM interaction for clarity and reduced hallucination:
- Utilized LLAMA-specific
[INST]prompt formatting for improved structure and quality. - Tuned the temperature hyperparameter to reduce randomness and improve answer clarity.
- Ensured only the most relevant retrieved chunks are passed to the model to minimize noise.
Challenges, Solutions, and Key Learnings
Challenge | Problem Description | Solution / Learning |
|---|---|---|
LLAMA Output Quality | Vague and slow responses initially. | Applied structured |
Context Isolation | Model retrieved context from other sessions or documents. | Implemented Pinecone namespaces per chat or session. |
Future Improvements Roadmap
- 🔄 Streaming Responses: Implement token-by-token streaming for better user experience.
- 🗃️ Persistent Chat History: Integrate DynamoDB to store and manage conversation history.
- 🔐 Improved Security: Enhance authentication and authorization mechanisms.
- 📊 Document Management: Add better metadata filtering and document versioning.
- 🧩 LLM Flexibility: Add additional LLMs support beyond current selection into the current plug-and-play architecture.
Key Takeaways
The project successfully delivered a real-world GenAI RAG system while navigating key engineering and cloud constraints:
- Demonstrated proficiency with AWS Bedrock, LangChain, and Pinecone.
- Focused on engineering trade-offs and building a production-ready serverless architecture.
- Worked under cloud, security, and scalability constraints.
Note: This project was developed as part of a confidential interview assignment. No proprietary documents or company data are included.
Your Take?
How did this piece land for you? React or drop your thoughts below.
Join the Conversation
X
More Stories from My Engineering Journey
Explore other projects and systems I've engineered.

OpenTax - A Blockchain-based Transparent Taxation System
An Open, Transparent & Scalable Taxation System
BlockchainEthereumSolidity

LOCALYSED - A Geospatial Locality Recommendation System
A full-stack geospatial and graph-based web application that recommends optimal residential localities in Mumbai.
Full StackGISData Engineering